Llama3 中文版本地环境搭建和部署实战ollama版
 admin 2024-11-13
111
admin 2024-11-13
111
这两天科技新闻中Llama3消息刷爆了,中国时间2024年4月19日0点0分,MetaLlama3发布。模型以开源形式提供,包含8B和70B两种参数规模,涵盖预训练和指令调优的变体。Llama3支持多种商业和研究用途,并已在多个行业标准测试中展示了其卓越的性能。
项目开源地址
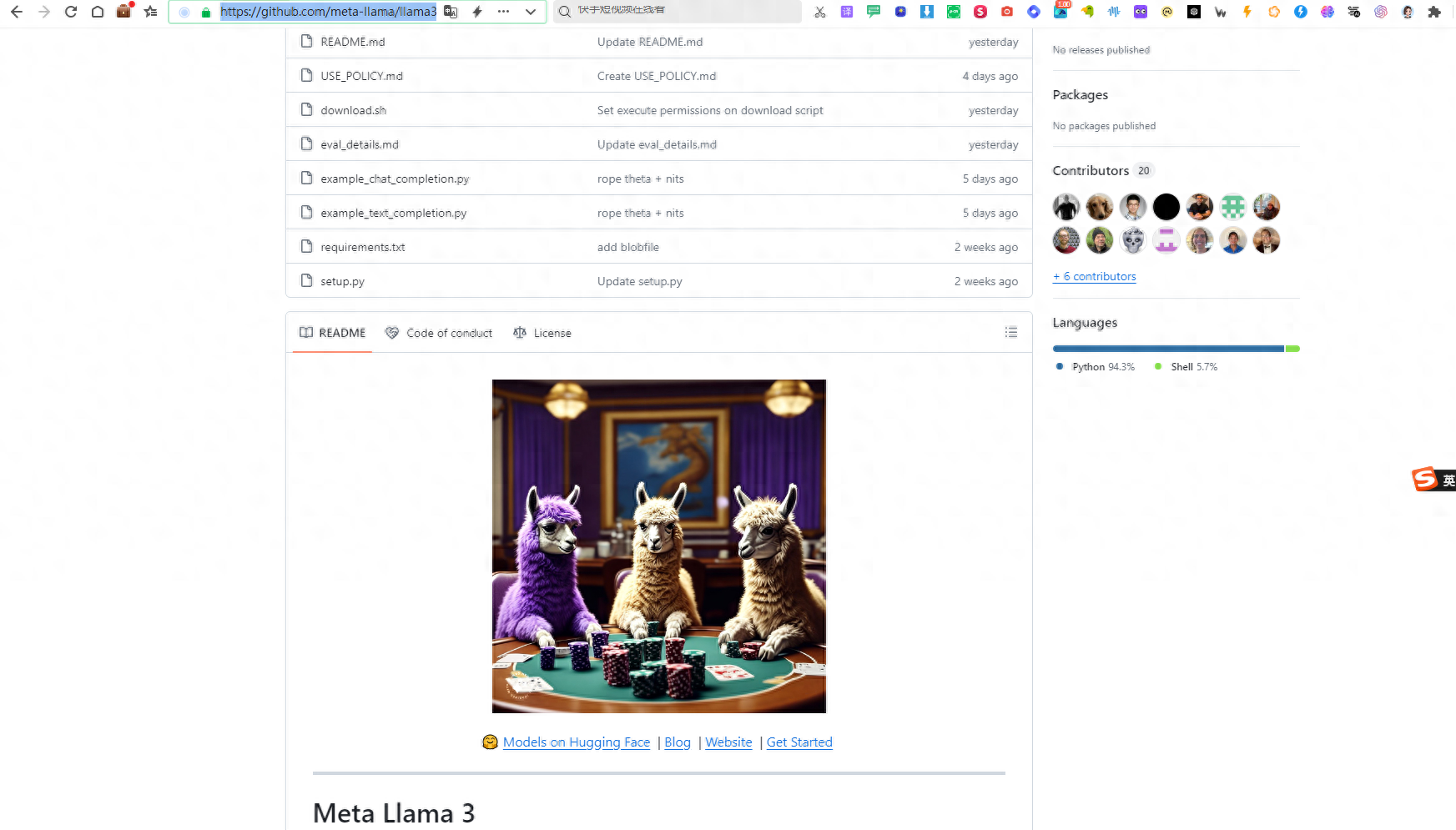
模型已经在HuggingFace上可以下载了
周末写了一篇文章关于《Llama3中文版本地环境搭建和部署实战》收到很多小伙伴欢迎,但是也有的小伙伴给我提出问题了。我介绍了原生通过python依赖环境安装的方式有点复杂,另外之前的项目中为了做4B量化在本地电脑上运行起来,我们也修改了作者的代码。有没有更简单方法来实现部署呢?因为这2天Llama3非常火爆,所以也出现了N个中文微调版本。
联通微调版:
Openbuddy微调版:
zhichen微调版:
shenzhi-wang微调版:
Rookie微调版:
破解安全限制系列(暂时只支持英文):
Unholy:
neural-chat:
dolphin:
llama3Moe增强版:计划中
llama3Pro(加block版):
ORPO+2block:
v-llama3多模态图文版:(支持视觉问答)
Bunny-Llama-3-8B-V:
llava-llama-3-8b:
多模态版本也出来了。真的是让人惊喜啊。本来计划打算使用项目对中文版大模型做模型转换,转换成GGUF支持ollama部署方式的模型格式了。今天在huggingface上面已经出现了带有GGUF格式的模型文件了
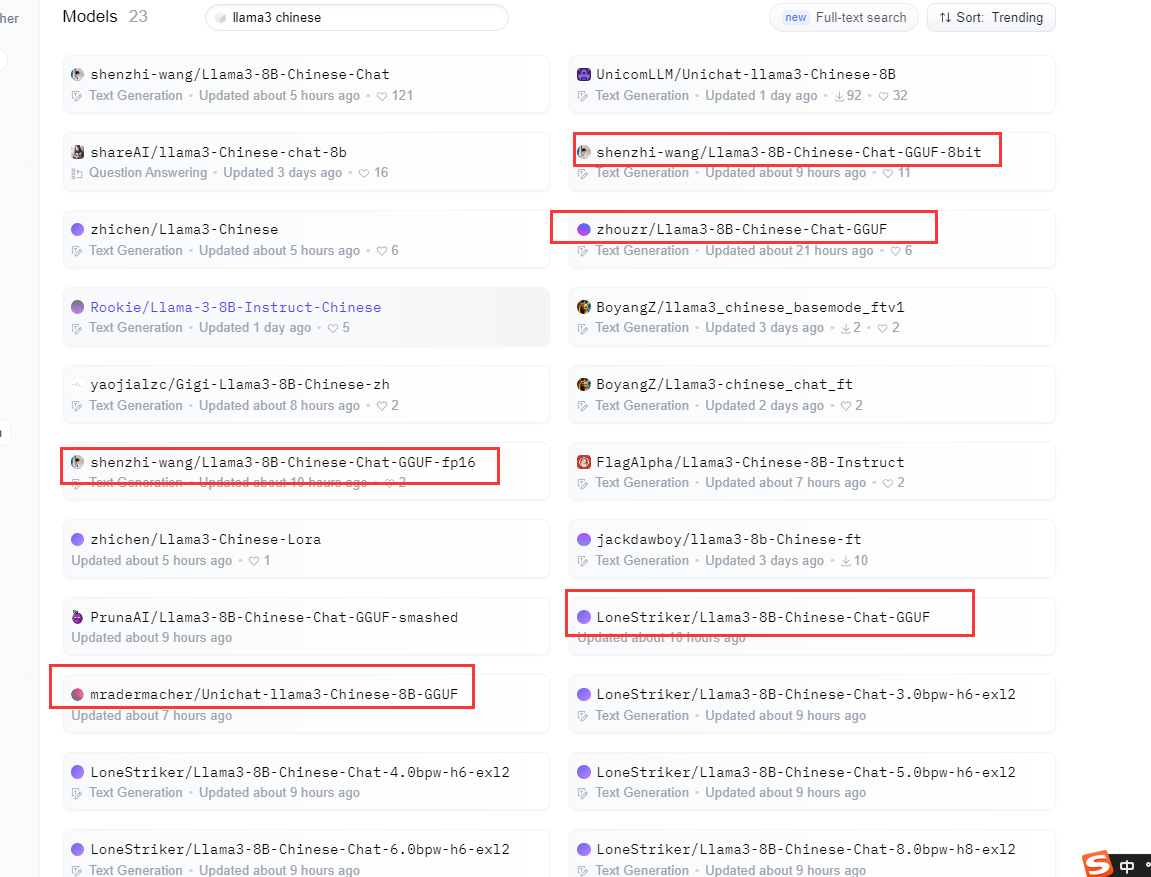
有了gguf格式的模型文件这样我们就不需要通过项目进行模型格式转换了。
另外ollama模型仓库中我们也发现了别人微调过中文版本Llama3
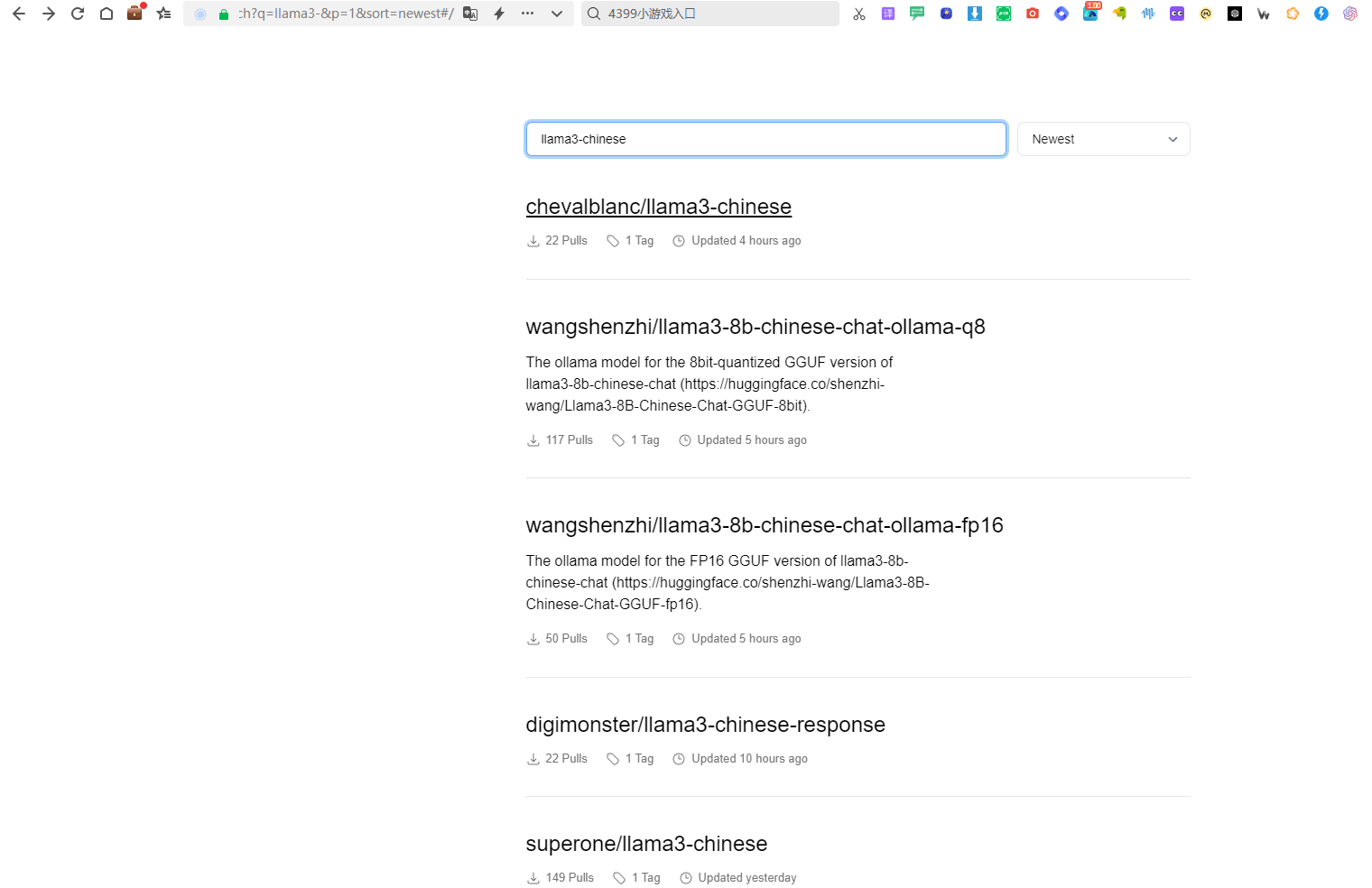
不过因为考虑到模型下载量,这里面模型质量到底是什么样子的赞也不干保证。所以我们还是在huggingface上面下载gguf格式的模型文件把。
1.模型下载
1.1我们选择zhouzr/Llama3-8B-Chinese-Chat-GGUF这个人模型下载,为什么选择这个模型呢,因为这个版本的模型支持多种量化模型(Q2、Q3、Q4、Q5、Q6)
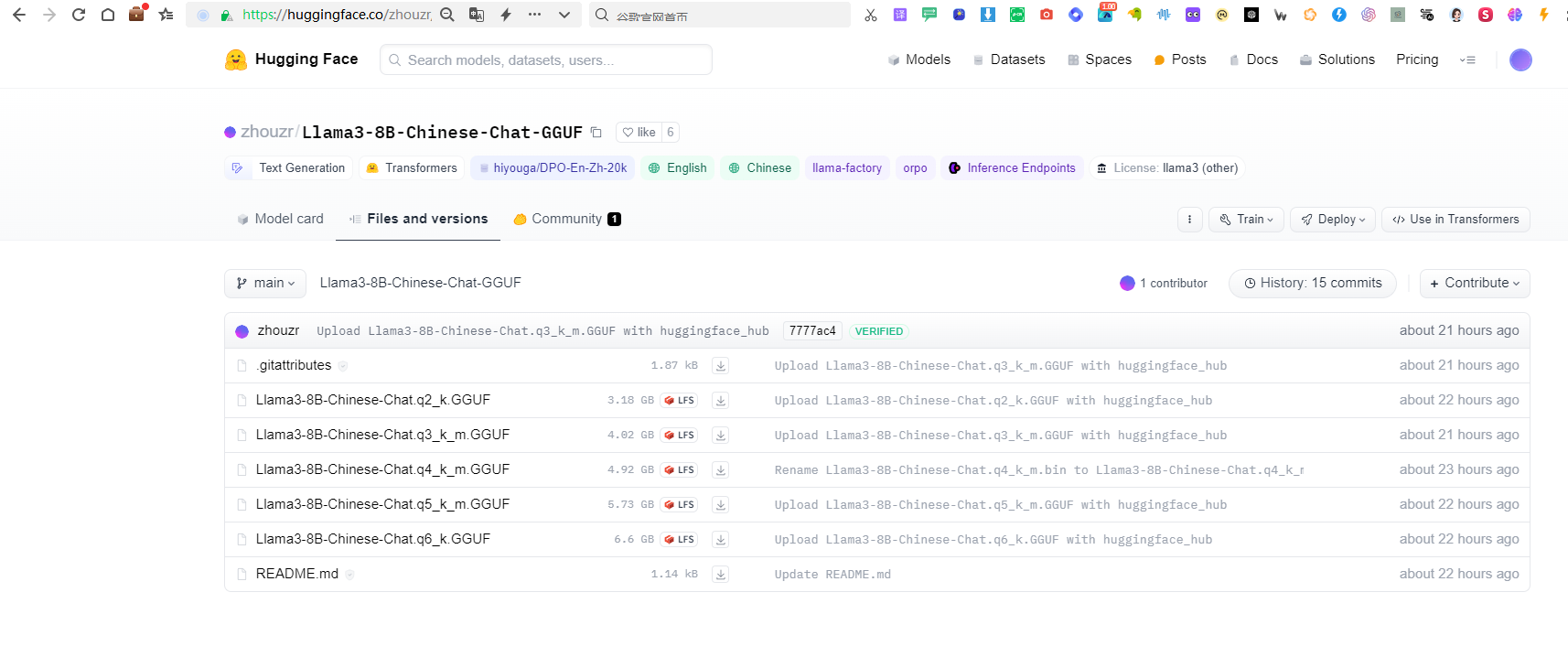
根据我们电脑上显卡内存大小我们选择_k_模型文件。
将这个模型文件下载到本地电脑上(F:\AI\Llama3-8B-Chinese-Chat-GGUF)

解下来我们需要编写Modelfile实现模型的自定义。Modelfile文件格式如下
FROM./_k_"""{{}}|start_header_id|system|_header_id|{{.System}}|eot_id|{{}}{{}}|start_header_id|user|_header_id|{{.Prompt}}|eot_id|{{}}|start_header_id|assistant|_header_id|{{.Response}}|eot_id|"""PARAMETERstop"|start_header_id|"PARAMETERstop"|_header_id|"PARAMETERstop"|eot_id|"PARAMETERstop"|reserved_special_token"编写好Modelfile文件,这个文件和模型文件放到同级目录

接下来我们在本地电脑上启动文件(关于ollama的安装这里就不在详细介绍了)
启动好后,我们在windowscmd窗口中执行ollamalist
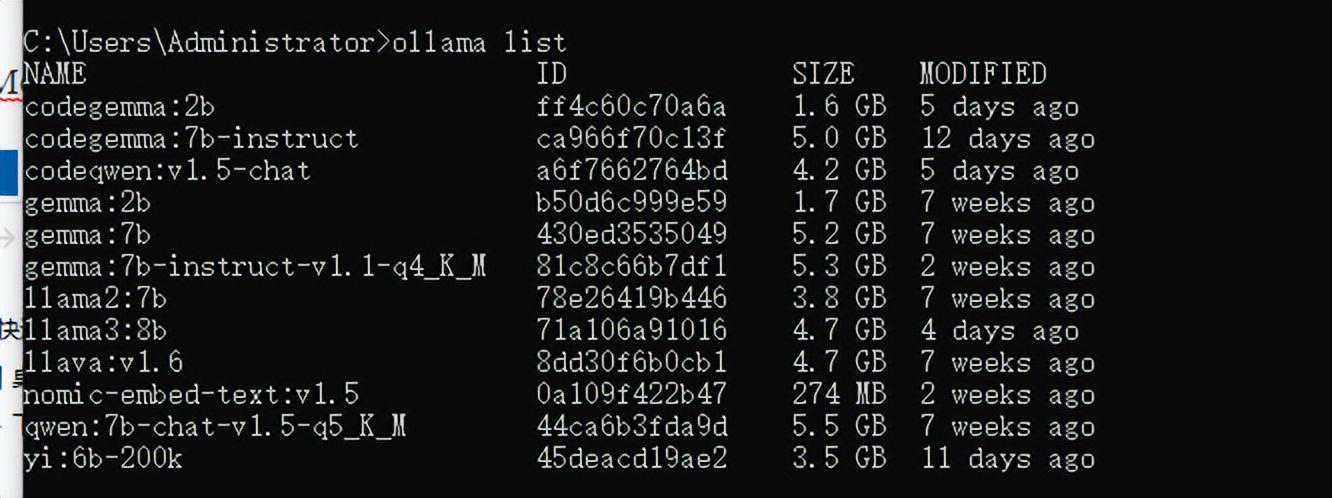
这里就可以列举出我们之前下载好的支持ollama模型镜像文件。
接下来我们切换到F:\AI\Llama3-8B-Chinese-Chat-GGUF模型文件目录下。

接下来我们输入自定义模型创建命令
ollamacreatellama3-Chinese:8B-fModelfile

接下来会显示模型创建记录
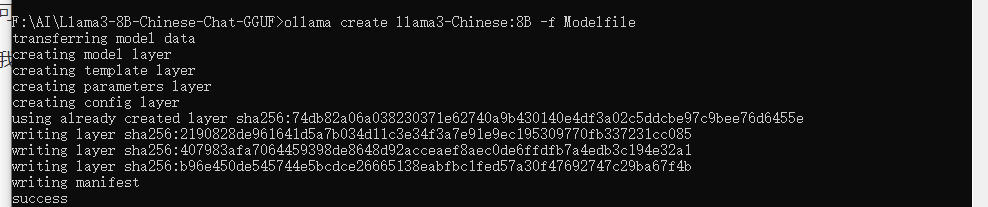
通过以上方式我们完成了模型自定义创建。
输入ollamalist这时候我们会看到新创建模型镜像文件
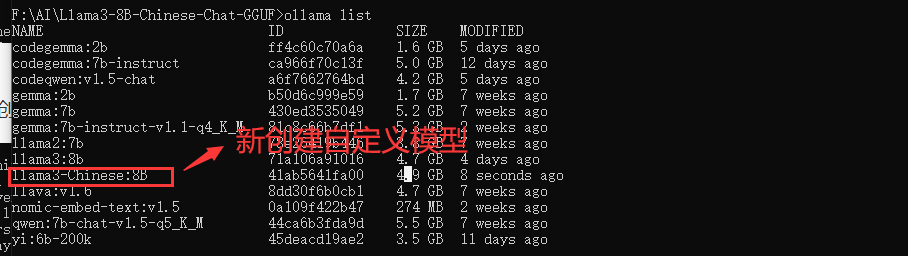
我们运行这个模型ollamarunllama3-Chinese:8B,输入完成后模型加载中,稍等1分钟左右进入命令行交互界面

我们输入问题“你好,你是谁?”这个时候模型给我们返回消息了,速度还挺快的。因为考虑到命令行输入不方面,另外也没办法实现多轮对话,我们可以借助chatbox客户端工具来测试。关于chatbox安装这个也不过多讲解。
chatbox下载地址
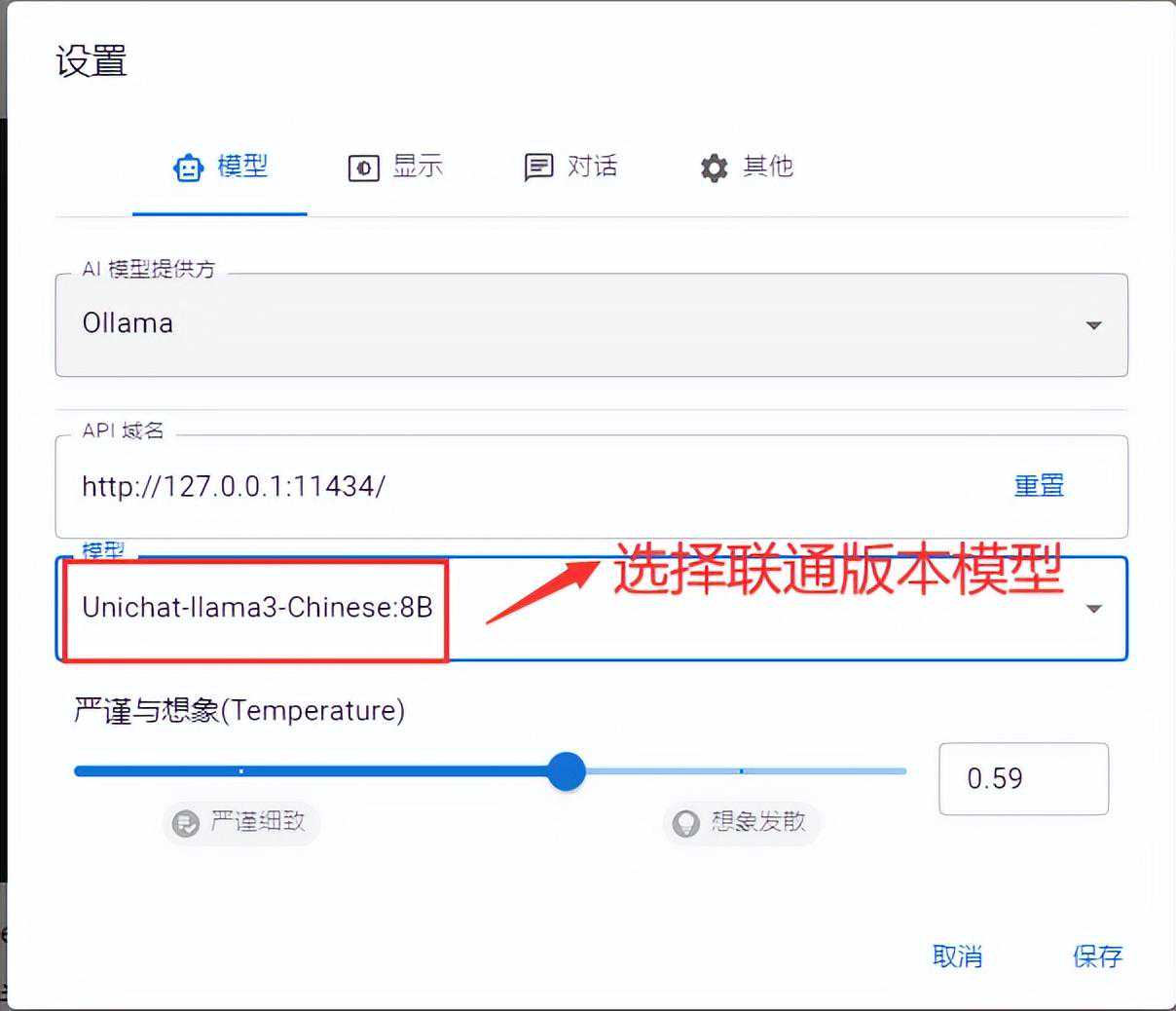
我们打开chatbox设置好ollama
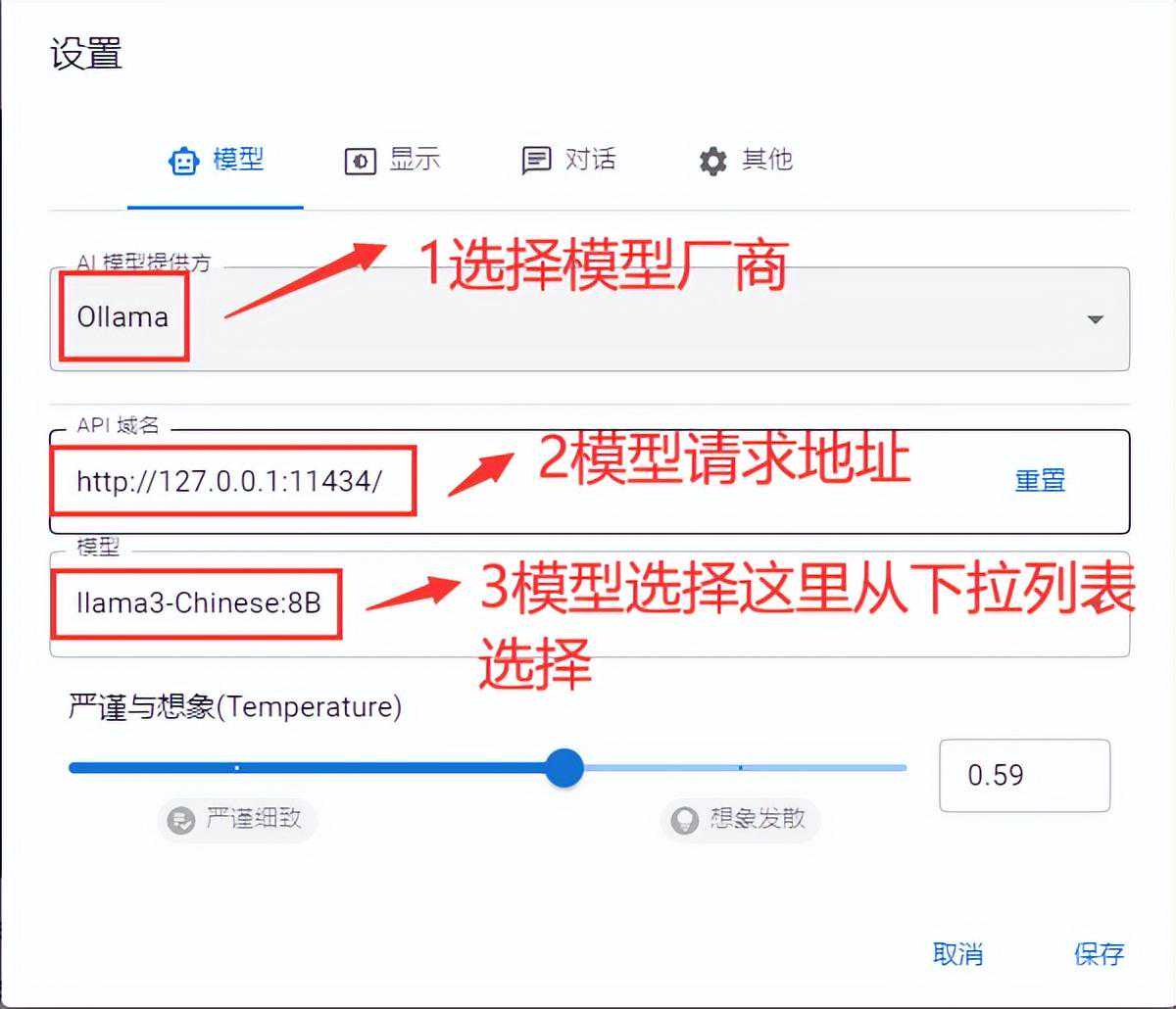
根据上面截图完成ollama在chatbox上的设置。其中3下拉模型是会加载ollamalist展现的模型,我们选择我们要测试的
llama3-Chinese:8B即可。
下面我们展示一下chatbox上的测试。
问题1鸡柳是鸡身上哪个部位啊?

问题2两千块钱买什么新车好?

问题3我同时吸入氧气和氢气是不是就等于我在喝水了

问题4蓝牙耳机坏了,去医院挂牙科还是耳科?

问题5给我用python写一个二分法算法
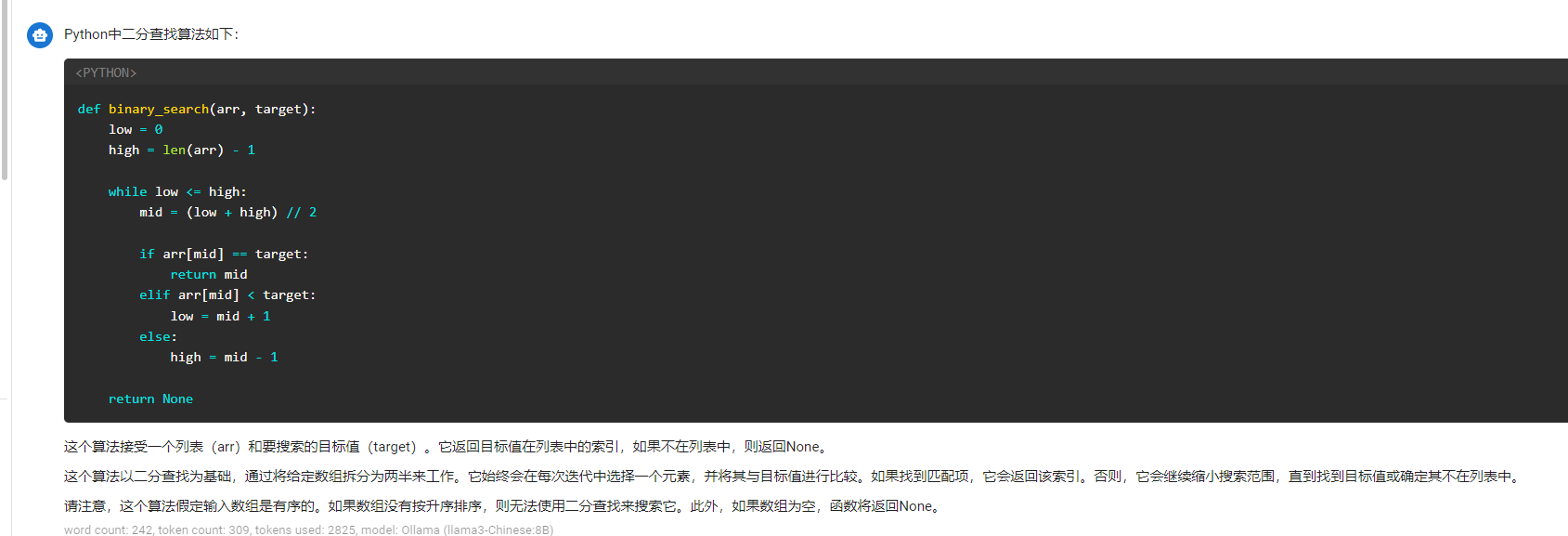
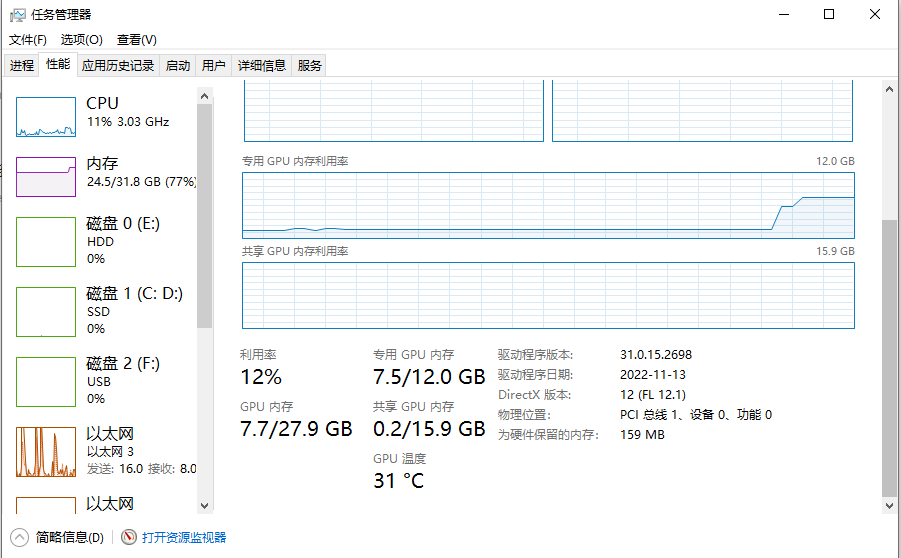
总体来说这个版本的量化还是不错的,运行速度也挺快的。另外我的显存消耗大概7.5G
1.2Unichat-llama3-Chinese-8B-GGUF
我们在huggingface看到还有联通版本的模型,下面我们也对这个模型进行测试一下。
下面的模型下载已经编写Modelfile和上面的类似,这里就不详细展开了。贴一下Modelfile文件
FROM./_K_"""{{}}|start_header_id|system|_header_id|{{.System}}|eot_id|{{}}{{}}|start_header_id|user|_header_id|{{.Prompt}}|eot_id|{{}}|start_header_id|assistant|_header_id|{{.Response}}|eot_id|"""PARAMETERstop"|start_header_id|"PARAMETERstop"|_header_id|"PARAMETERstop"|eot_id|"PARAMETERstop"|reserved_special_token"创建模型
ollamacreateUnichat-llama3-Chinese:8B-fModelfile
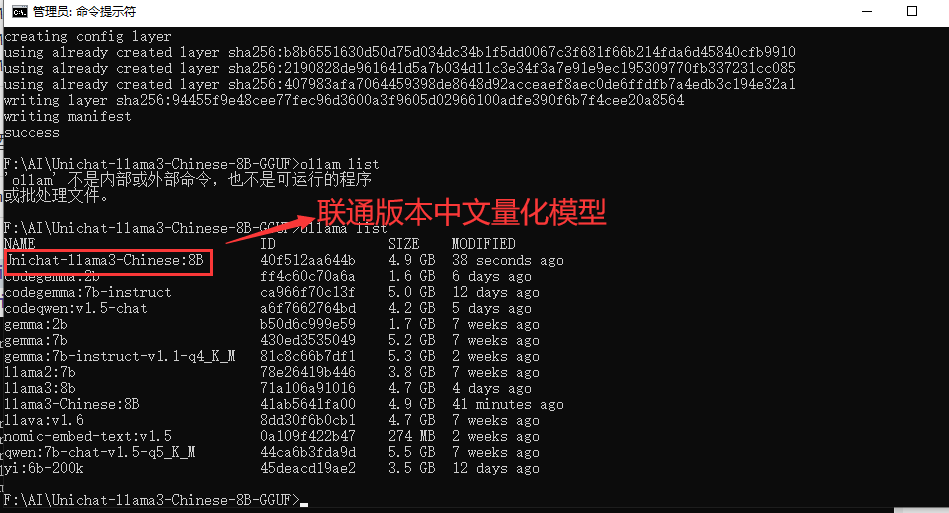
下面我们之间用chatbox对联通版本量化模型测试对比一下效果
我们重新开一个聊天窗口
问题1:鸡柳是鸡身上哪个部位啊?

这个解释的不好。
问题2:两千块钱买什么新车好?

这个没回答到点子上。
问题3:我同时吸入氧气和氢气是不是就等于我在喝水了

这个回答让我比较失望。
问题4:蓝牙耳机坏了,去医院挂牙科还是耳科?

答非所问。
总结:这个联通版本模型测试下来完全不行,对比下来是没有上面的第一个模型效果好,看来微调还是要看下载量和口碑等要素。
说明:以上测试的题目从“ruzhiba”题库里面选取的,有需要的小伙伴可以留言,私信给我。








- 同类文章
























- 友情链接
-