Llama3 中文版模型微调笔记,小白也能学会
 admin 2024-11-13
123
admin 2024-11-13
123
中国时间2024年4月19日0点0分,MetaLlama3发布。经过一周的时间目前huggingface上面已经有好几款Llama38B版本的中文微调模型了。
。
shareAI系列:
base预训练+直接中文sft版:
训练数据:
V1版
OpenCSG满速下载:
WiseModel满速下载:
V2版
modelscope:
Instruct+继续中文sft版:
Base预训练+海量中文优质数据增量预训练:正在进行中
70b中文版:计划中
下面几个版本,因对话格式不同暂时不支持网页部署,需要用
fastchat
体验:
Instruct+DPO偏好中文版:
Base+ORPO偏好中文版:
llama3Pro(加block版,推荐尝试该方案上做更多探索):
首个扩展2Block+ORPO偏好对齐:
llama3Moe增强版:计划中
联通微调版:
Openbuddy微调版:
zhichen微调版:
shenzhi-wang微调版:
Rookie微调版:
破解安全限制系列(暂时只支持英文):
Unholy:
neural-chat:
dolphin:
v-llama3多模态图文版:(支持视觉问答)
Bunny-Llama-3-8B-V:
llava-llama-3-8b:
agent工具能力增强版:
ModelScopeChineseAgent版V1:
每天还在持续更新中。看到这么多中文微调模型,那么我们有没有办法自己也微调一个版本的中文Llama3模型呢?
话不多说下面告诉大家如何微调这个Llama3中文模型。
1.登录Colabnotebook
首先我们需要保证自己有一个google账号,没有google账号的自行搜索一下,然后注册一个google账号。有了google账号很多google家的产品都可以使用了。
登录Colabnotebook
我会看到这个Colab脚本里面的相关步骤。
大致分为1.安装LLaMAFactory依赖
2.检查GPU环境
3.新自我认知数据集
4.模型训练
5.模型推理
安装LLaMAFactory依赖
下载好LLaMAFactory项目后,我们在左边目录结构中会看到下载后的代码结构
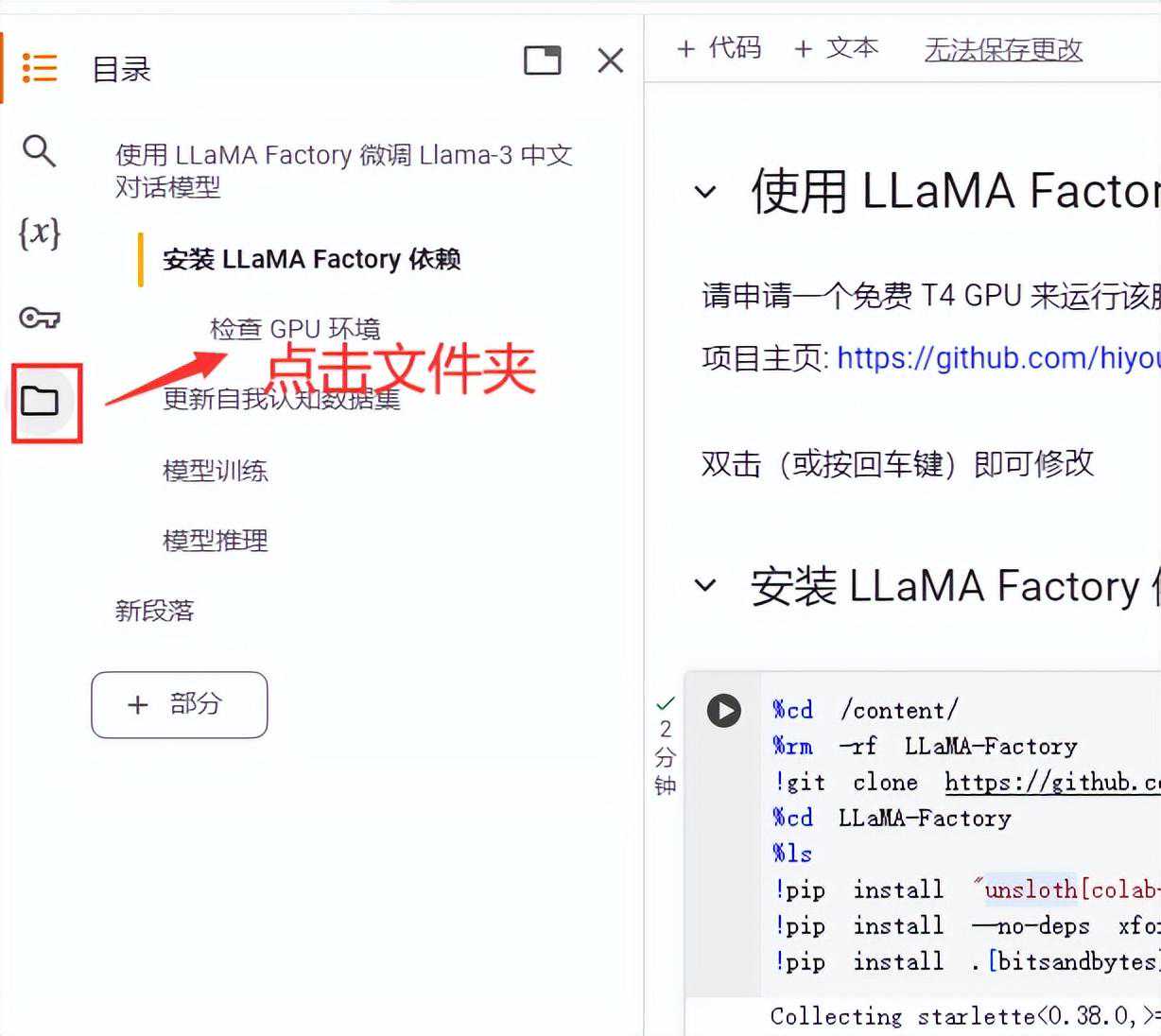
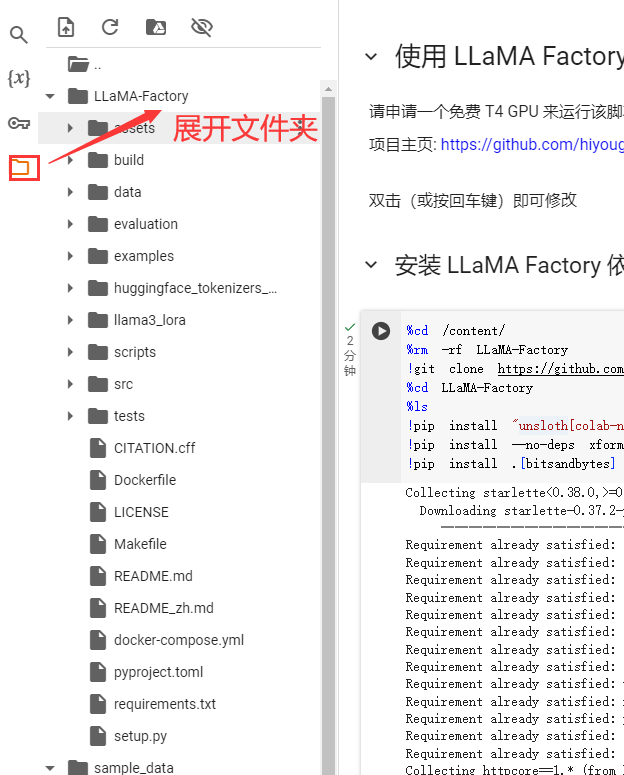
运行这个安装LLaMAFactory依赖大概花费2分钟。
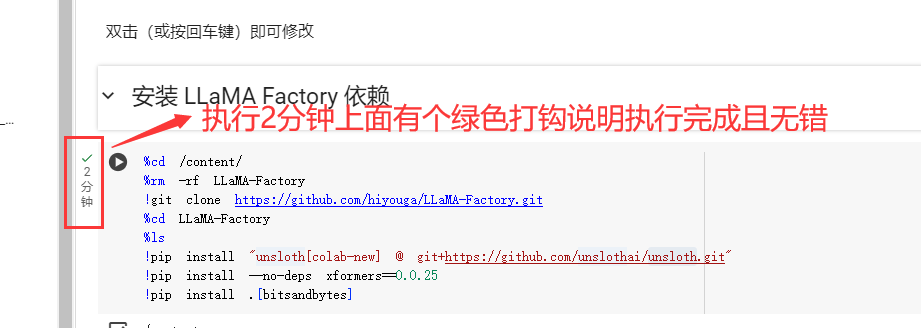
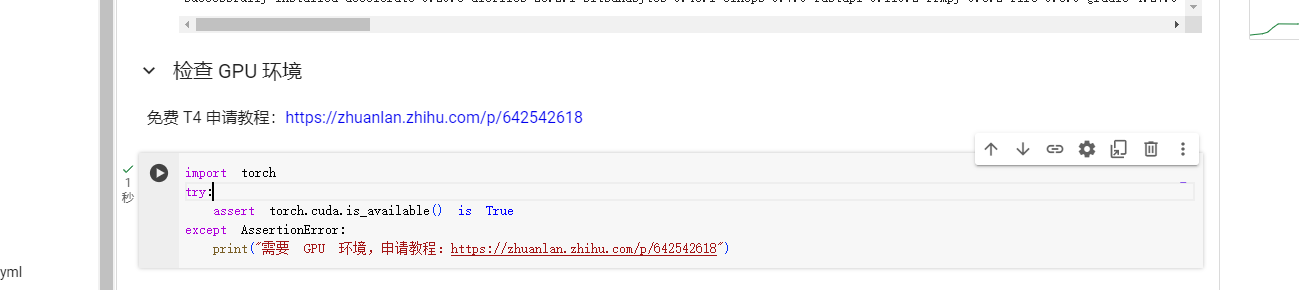
3.检查GPU环境
鼠标滑动到检查GPU环境代码执行栏目
4.更新自我认知数据集
这个地方稍微讲解一下,因为我们是需要训练自己的数据集的,所以是需要上传自己的数据集的。
数据集在哪个目录下呢?在LLaMAFactory\data\
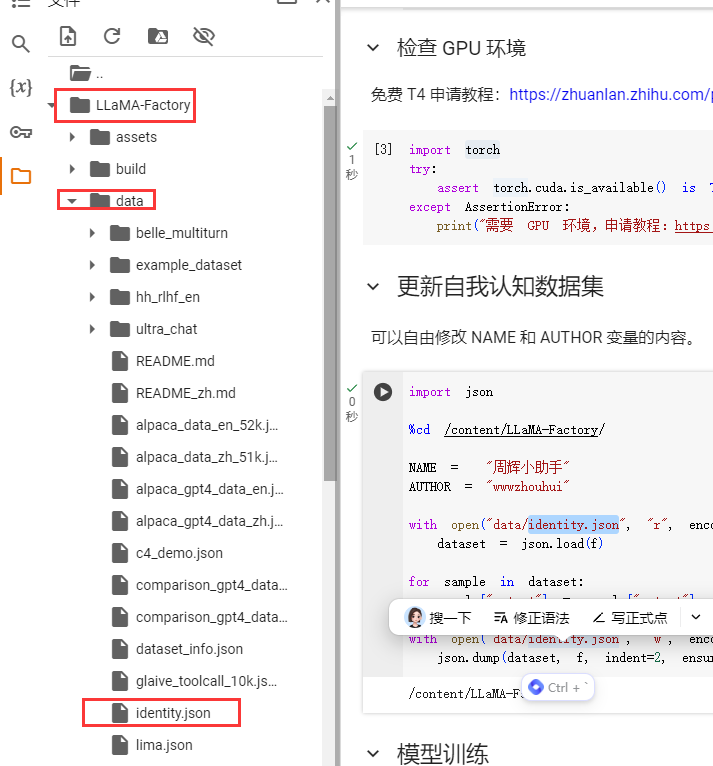
我们可以双击打开这个在colab右边窗体中会出现数据集,数据集格式是json格式的

这里面我们可以修改里面的数据集或者你在huggingface上下载别人整理过的优质数据集做训练也是可以的。
我这里提供一个huggingface上一个数据集给大家看一下。
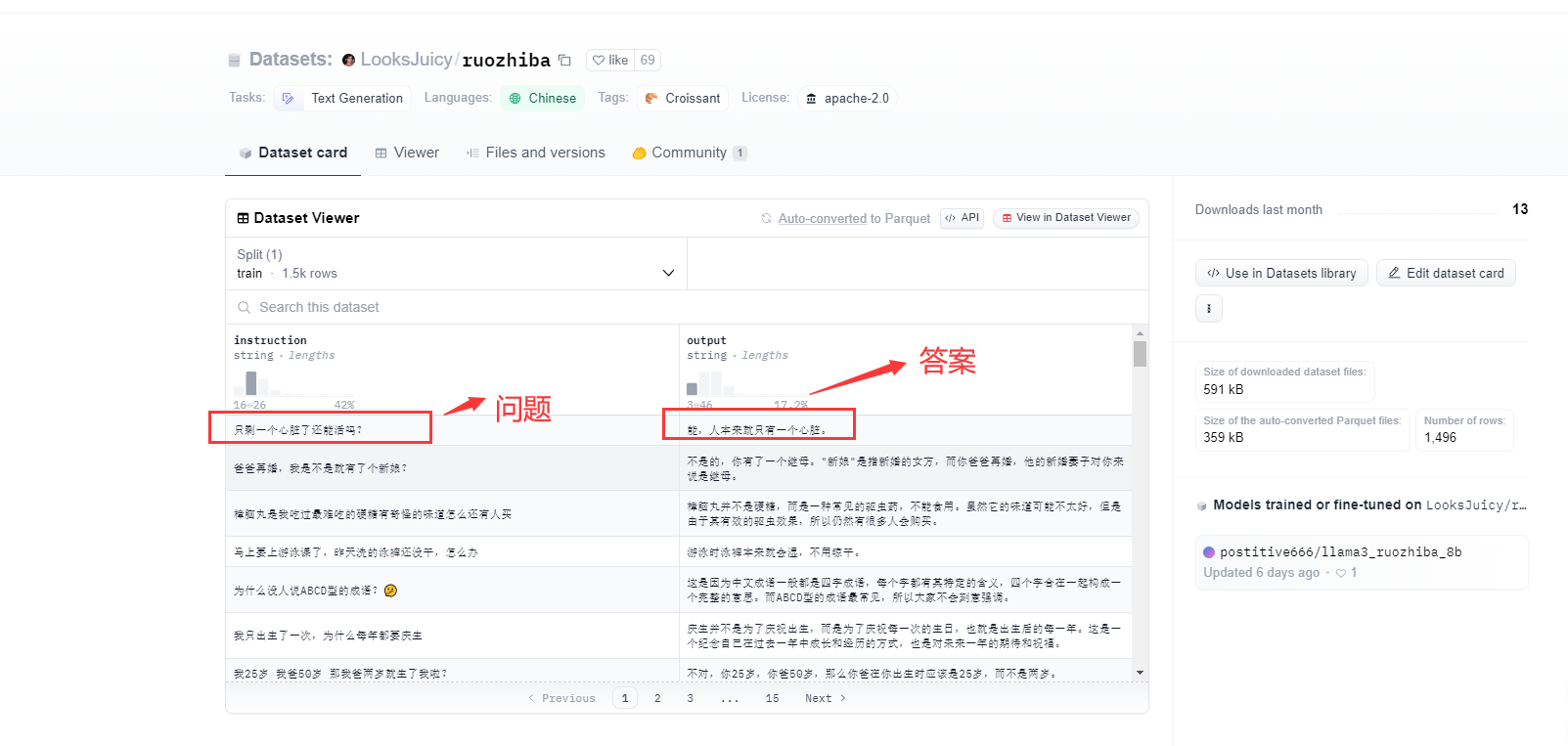
问题整理成问答对的形式里面的内容换成你整理的或者下载优质数据集即可。
我这里最偷懒的办法就是我还是用原来LLaMAFactory\data\自己的数据集我只修改NAME和AUTHOR
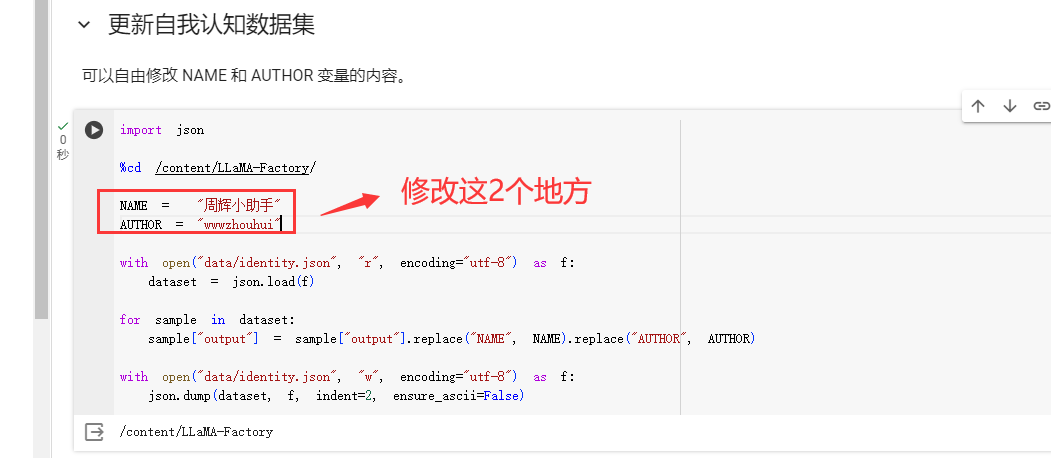
5.模型训练
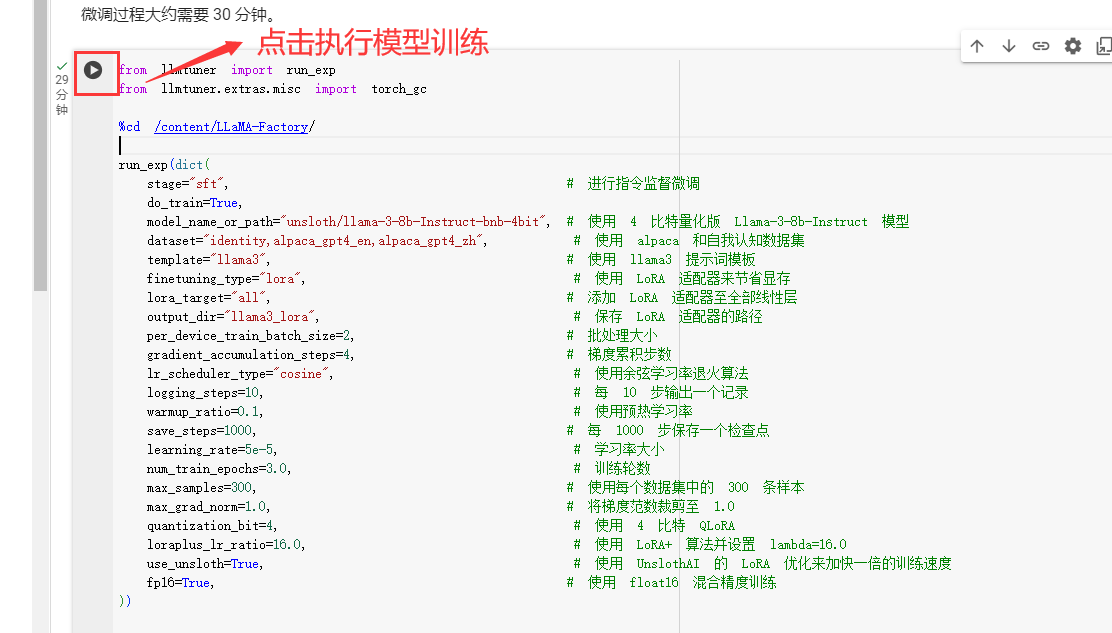
下面这块简单讲解一下
这块其实是下载llama-3-8b-Instruct-bnb-4bit模型。
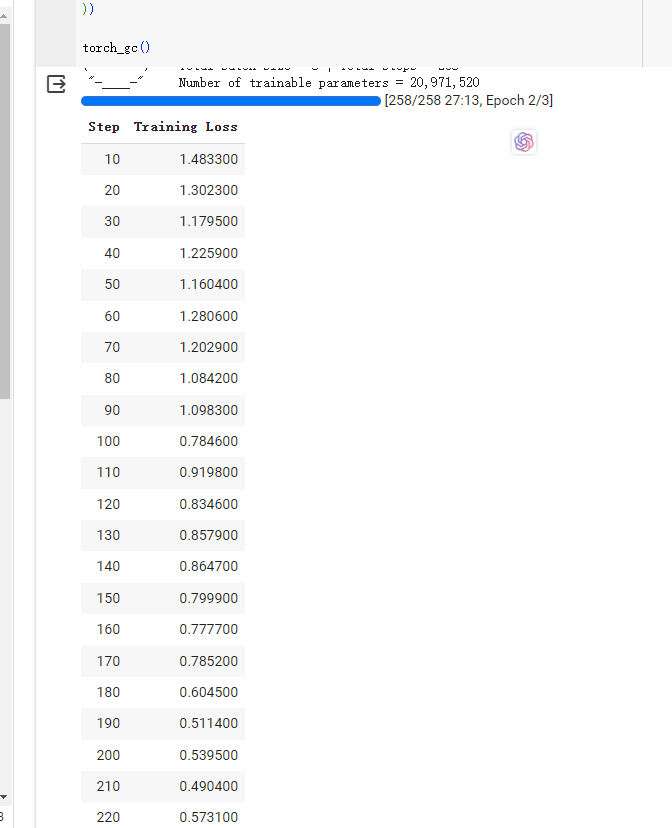
这个是模型训练迭代步数。大概30分钟完成模型微调,这里结束一下,因为我们只是改了个名称和作者做微调,所以模型训练时间会比较短,如果训练数据集多这个训练时间会很长,几天几十天都不等。而且模型训练需要好的显卡比如A100显卡,而且还不是一张显卡。
6.模型推理
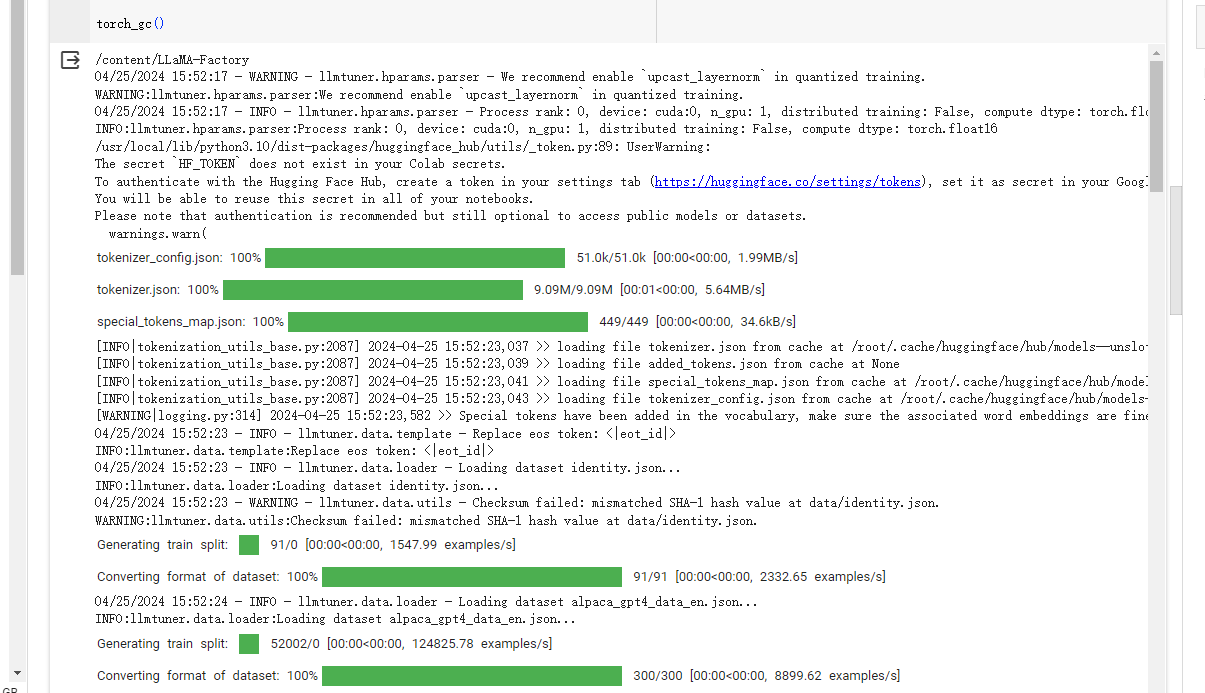
模型训练完成后,我们需要验证一下微调后的效果。我们在推理代码执行

运行后微调后的模型加载到显存中,这个时候会出现交互对话框
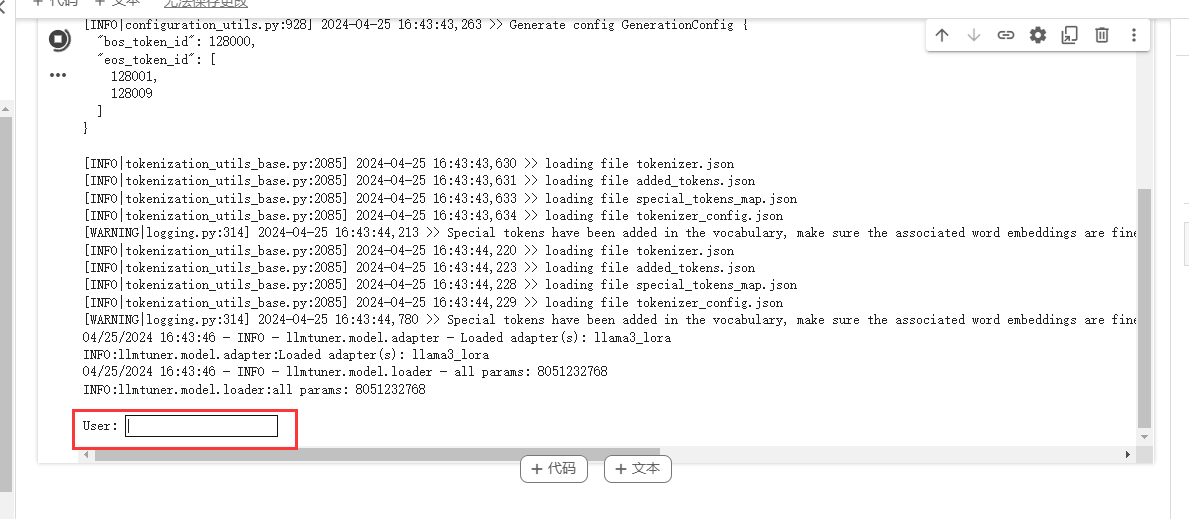
我输入问题。你好,你是谁?
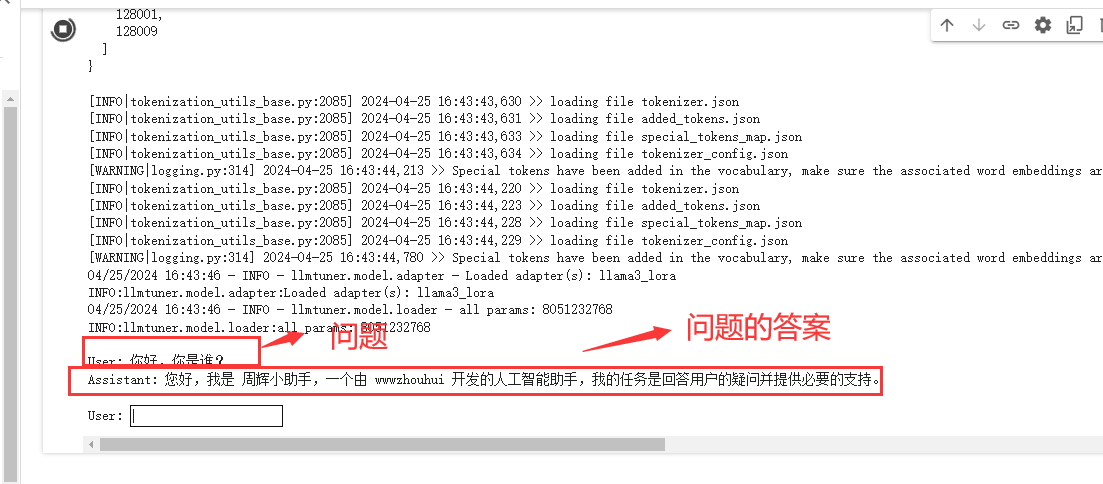
看到了没,这个时候模型已经正确回答我微调后的返回的结果了。到这里简单的模型微调就完成了,是不是非常简单啊。








- 同类文章


























- 友情链接
-